AI Native Coding
「Plan, search, or build anything」—— 在 AI 原生编程里,规划和构建可以有不同的起点与节奏。本文介绍 AI Native Coding 的基本概念、常见工作流与规范,以及 Vibe 与 Spec 两种模式的差异与适用场景。
如果你是第一次看这篇,建议先读“先看结论”“什么是 AI Native Coding”“Vibe 与 Spec:概念与区别”这三节,再按需要继续往下看。
先看结论
- AI Native Coding 不是“让 AI 帮你写几段代码”,而是把 AI 纳入需求、设计、实现与验证的完整协作链路。
- 当需求模糊、想快速试错时,更适合用 Vibe;当需求明确、需要协作和可追溯时,更适合用 Spec。
- 想让 AI 长期稳定地产出,真正依赖的不是单条 prompt,而是规则、文档、测试和工作流。
什么是 AI Native Coding
AI Native Coding 指以 AI 为第一协作对象的开发方式:从需求探索、方案设计到代码实现,都围绕与 AI 的对话与协作展开,而不是把 AI 仅当作「写代码的助手」。
核心特点包括:
- 对话优先:用自然语言描述目标、约束和上下文,让 AI 参与理解与拆解。
- 迭代式构建:在实现过程中持续澄清、修正和扩展,而不是一次性写完再改。
- 规范与上下文可复用:通过 PRD、SPEC、Skills、Rules 等把约定沉淀下来,让 AI 在不同会话中保持一致行为。
一、Vibe Coding 氛围编程
通过自然语言和 AI 对话,让 AI 帮你写代码,你只需要描述需求、测试结果、指导方向。
适合:适合快速试想法、做原型、改小功能。
二、Harness Engineering 驾驭工程
Harness engineering 可以大白话理解成:不是只会“让 AI 写代码”,而是把 AI 放进一套能稳定干活的工作环境里,让它少犯错、犯错后能自动纠正。 它的重点不是“怎么把一句提示词写得更好”,而是“怎么把整个系统搭好,让 AI 在这个系统里可靠地完成任务”。 简单说就是:人负责设计规则、边界、反馈机制;AI 负责执行具体工作。
Harness Engineering 核心思想:
- 上下文管理:给 AI 合适的信息,别喂太多垃圾上下文。
- 结构约束:规定它能改哪里、不能改哪里。
- 测试和校验:让 AI 每次做完都能自动检查。
- 反馈回路:做错了就修,修完再验证,形成闭环。
- 任务切分:把大目标拆成 AI 更容易执行的小步骤。
它和提示词工程的区别:
- 提示词工程:更像是“怎么跟 AI 说话,让它这次答对”
- Harness engineering:更像是“给 AI 配一套好用的工位、工具、检查机制和回路,让它长期稳定答对”
适合:适合长期开发、复杂功能、团队协作。
三、Ralph Wiggum Loop
Ralph Wiggum Loop 是一种让 AI 持续改进的循环机制,它通过让 AI 自己发现问题、提出解决方案、执行修复、验证结果,形成一个闭环。
工作流程大概是这样的:
- 先写一份 PRD(产品需求文档),把要做的功能拆解成一个个清晰的检查项
- 让 AI 智能体开始执行,每次从检查清单中取出未完成的任务
- AI 完成一个任务后,通过 Git 提交代码并记录进度
- 以全新的上下文开始新一轮迭代,继续处理剩余任务
- 不断循环,直到所有检查项完成
这种模式的巧妙之处在于,每轮循环都以干净的上下文开始(通过 Git 和文件来持久化进度),避免了长对话中 AI 容易断片儿的问题。而且可以无人值守地运行,你写好 PRD 就可以去睡觉了,第二天起来检查成果就行。
适合:功能明确且可拆解的项目、想让 AI 无人值守地干活、任务量大但单个任务相对独立。
四、BMAD 敏捷 AI 开发方法
BMAD-METHOD(Breakthrough Method of Agile AI-Driven Development,突破性敏捷 AI 驱动开发方法)是一套系统化的 AI 智能体开发框架,目标是将原本混乱的 AI 编程过程变得结构化、可复用。
三层核心思想:
- 第一层思想是“先规划,后编码”:BMAD 强调先由分析、产品、架构等角色把 PRD、用户故事、架构说明等文档梳理清楚,再进入开发,从而减少 AI 直接写代码时常见的跑偏和返工。
- 第二层思想是“角色分工”:它不是让一个 AI 包办所有事,而是把任务拆给 Analyst、PM、Architect、Developer、QA 等不同角色,形成类似真实团队的交接流程。
- 第三层思想是“上下文工程和可审计性”:通过把需求、约束、设计和历史决策嵌入工作流,BMAD 试图降低上下文漂移,让输出更可预测,也更容易治理和复盘。
典型流程
不少资料把 BMAD 概括为一个分阶段流程,例如 Analysis → Planning → Solutioning → Implementation,先定义问题和约束,再拆成故事和验收标准,随后补齐设计并执行实现。 在更完整的用法里,前期会先产出 project brief、PRD 和 architecture 文档,之后再由开发代理按故事逐步实现,这本质上是一种 spec-driven 的 AI 开发方式
适合:从零开始的完整项目、需要走完分析-设计-开发全流程的产品、团队想要标准化 AI 开发流程。
五、SDD 规范驱动开发
SDD(Spec-Driven Development 规范驱动开发)是 AI 时代的一种新型开发方法论,强调在编码之前先创建明确的、AI 能直接理解和执行的规范文档。
传统开发流程是:想到什么写什么,边写边改,最后再补文档。这样容易导致需求不清晰、代码和文档对不上。
而 SDD 的思路正好相反:先把需求写成规范文档,并且把规范文档当作代码的唯一真相来源。
你可以把规范文档理解为 “项目宪法”,它包含了详细的需求描述、系统设计和接口定义。AI 必须严格遵守这些条文来生成代码,确保产出完全符合预期。
为什么 SDD 越来越受重视?
- 因为 AI 生成代码的质量直接取决于上下文的清晰度,而不仅仅是依靠提示词技巧。一个清晰的规范文档能比任何 Prompt 黑魔法更有效地减少错误。
SDD 的典型工作流程:
- Constitution 制定准则:定义项目的基本原则、代码规范、性能标准
- Specify 编写规范:描述要做什么功能、为什么做、用户需求是什么
- Clarify 澄清疑问:让 AI 提出结构化问题,明确边界情况和错误处理
- Plan 制定方案:确定技术栈、系统架构、数据模型、API 接口
- Tasks 拆解任务:把计划拆解成可执行的任务列表,标注依赖关系和优先级
- Implement 执行实现:AI 按照任务列表生成代码,人类验证
适合场景:需求复杂且明确的项目、对代码质量要求高的场景、团队多人协作开发。
注意,这些模式之间并不是互相排斥的,实际开发中完全可以混着用。比如用 SDD 先把规范写好,再用 BMAD 的角色化智能体去执行,底层用 Harness Engineering 的思路来约束 AI 的行为。灵活组合,效果更佳。
常见工作流(Flow)
不同团队和场景下,流程会有所差异,但大体可以归纳为两类主流程:
- 探索优先(Vibe):先通过对话探索想法和需求,再在迭代中逐步实现。
- 规划优先(Spec):先写好需求与设计(PRD/SPEC/Test Case),再让 AI 按文档实现。
下面会单独说明这两种模式的概念与区别。除此之外,还有一类常见流程:
- 文档驱动开发:在任意模块(含 PRD/SPEC/测试用例)中,按「需求 → 设计 → 测试用例 → 实现 → 单测」顺序推进,并保持文档与代码同步更新。适合需要可追溯、可评审的协作场景。
规范(Conventions)
在 AI Native 协作中,规范用于减少歧义、统一风格,并让 AI 行为可预期。常见形式包括:
| 类型 | 说明 | 示例 |
|---|---|---|
| PRD / 需求文档 | 描述做什么、为谁做、验收标准 | 功能需求、用户故事、验收条件 |
| SPEC / 设计说明 | 描述怎么做、接口与结构 | 接口设计、状态设计、交互说明 |
| 测试用例(Test Case) | Given-When-Then 等结构化用例 | 先写用例再实现,保证覆盖 |
| Skills / Rules | 项目级或全局的 AI 行为约定 | 代码风格、目录结构、必读文档 |
| MCP / 工具 | 为 AI 提供统一的外部能力 | 搜索、执行命令、读文档等 |
建议在项目中显式维护这些规范,并在提示或 Skills 中引用,让 AI 在写代码前「先看文档再动手」。
Vibe 与 Spec:概念与区别
很多 AI 编程产品会用 Vibe 和 Spec 来区分两种构建方式,可以简单理解为:先聊再建 vs 先规划再建。
Vibe(先聊天,再构建)
一句话:Chat first, then build. Explore ideas and iterate as you discover needs.
先对话、再实现;在发现需求的过程中探索想法并迭代。
特点:
- 不要求一开始就有完整需求或设计。
- 通过和 AI 的对话逐步澄清「要什么」和「怎么做」。
- 适合快速试错、验证想法、边做边改。
适用于:
- 快速探索与验证(Rapid exploration and testing)
- 需求尚不清晰时的构建(Building when requirements are unclear)
- 实现一个相对独立的任务(Implementing a task)
Spec(先规划,再构建)
一句话:Plan first, then build. Create requirements and design before coding starts.
先规划、再实现;在编码开始前完成需求与设计。
特点:
- 先写清楚需求、接口、行为或测试用例,再让 AI 按文档实现。
- 强调前置思考与结构化,减少返工和理解偏差。
- 适合需要评审、协作或长期维护的功能。
适用于:
- 深入思考功能(Thinking through features in-depth)
- 需要前期规划的项目(Projects needing upfront planning)
- 以结构化方式构建功能(Building features in a structured way)
对比小结
| 维度 | Vibe | Spec |
|---|---|---|
| 顺序 | 先聊再建 | 先规划再建 |
| 需求 | 可在对话中逐步发现 | 事先用文档定义 |
| 节奏 | 探索、迭代、试错 | 设计、评审、再实现 |
| 典型场景 | 原型、小任务、需求模糊 | 正式需求、多人协作、可追溯 |
实际开发中可以根据任务性质混合使用:例如用 Vibe 做早期探索和原型,再用 Spec 把确定下来的部分写成 PRD/SPEC 和测试用例,交给 AI 实现与单测。
延伸阅读
- 本站 AI 工具介绍、AI 使用技巧 可配合使用,提升与 AI 协作时的环境与效率。
- 若你使用 Cursor,可结合项目内 文档驱动开发 的 Skill(PRD/SPEC/Test Case 流程)与 Rules,让 AI 先读文档再写代码,保持文档与实现同步。
AI Agent 与 LLM(大语言模型)的核心区别
AI Agent(智能体)和 LLM(大语言模型,以 OpenAI GPT 系列等为代表)是包含与被包含、层阶与能力完全不同的两类 AI 体系:LLM 是 AI Agent 的核心“大脑”/基础能力组件,而 AI Agent 是基于大语言模型(如 GPT)扩展出的、具备自主感知、决策、行动能力的完整智能系统。
简单来说:LLM 是“能理解和生成语言的智能大脑”,AI Agent 是“装上了眼睛(感知)、手脚(工具)、思维(规划),能自己完成任务的智能机器人”。
二者的核心差异体现在定位、核心能力、工作模式、解决问题的维度等多个层面,以下从关键维度做清晰拆解,同时补充二者的关联,帮你彻底厘清边界:
一、核心定位与本质不同
LLM(大语言模型)
- 本质:语言理解与生成的基础模型,核心是对文本数据的建模,实现“输入文本→理解语义→生成符合逻辑、上下文的输出文本”。
- 定位:AI领域的基础能力组件,是“感知和思考的核心模块”,但本身不具备自主规划、工具调用、环境交互的能力。
- 核心价值:解决“语义理解、内容生成、知识问答”等纯语言层面的问题,是构建更复杂AI系统的基础底座。
AI Agent
- 本质:具备自主决策和行动能力的智能系统,是大语言模型结合感知模块、规划模块、工具调用模块、记忆模块形成的完整智能体。
- 定位:AI领域的应用型智能系统,是“能独立完成复杂任务的执行者”,核心目标是解决现实世界的具体问题。
- 核心价值:将大语言模型的“认知能力”转化为“行动能力”,实现从“能说”到“会做”的跨越。
二、核心能力的核心差异(最关键)
LLM 的能力集中在语言层,而 AI Agent 在 LLM 的语言能力基础上,新增了四大核心能力,这也是二者的本质区别:
| 能力维度 | LLM(大语言模型) | AI Agent(智能体) |
|---|---|---|
| 语言理解/生成 | ✅ 核心能力,极致优化(如语义理解、逻辑推理、内容创作) | ✅ 基于大语言模型(如 GPT)实现,是基础能力 |
| 自主规划能力 | ❌ 无,仅能根据单次输入做即时响应,无法拆分复杂任务 | ✅ 能将复杂目标拆分为多个子任务,制定执行步骤(如“写周报”拆分为“整理数据→撰写框架→填充内容→校对”) |
| 工具调用能力 | ❌ 原生无,需通过插件/API二次开发才能实现简单调用 | ✅ 核心能力,能自主选择并调用外部工具(如计算器、Excel、浏览器、代码编译器、第三方API)解决自身能力外的问题 |
| 环境交互能力 | ❌ 无,仅在“文本输入-文本输出”的封闭循环中工作 | ✅ 能感知外部环境(如读取文件、获取网络信息、操作软件),并根据环境反馈调整行动 |
| 长期记忆能力 | ❌ 仅具备短期上下文记忆,会话结束后记忆丢失,无法跨会话积累知识 | ✅ 具备短期记忆+长期记忆体系,能存储、检索、复用历史交互和任务信息,跨会话保持任务连贯性 |
典型能力对比案例
LLM:问“2026年中国GDP预计是多少?”,LLM 仅能基于训练数据(如 2025 年及之前)做推测,无法实时联网获取最新数据,答案大概率是过时或模糊的;
AI Agent:接到同样问题,会自主规划→调用“浏览器/财经API”工具→实时获取2026年最新GDP预测数据→整理数据→生成精准答案,全程无需人工干预。
LLM:问“帮我计算100个股票的市盈率并排序”,LLM 仅能给出计算公式,无法直接操作Excel/数据库完成计算;
AI Agent:会自主调用Excel/Python工具→读取股票数据→执行计算→排序→生成结果表格,直接交付最终成果。
三、工作模式与交互逻辑不同
LLM:单次输入-单次输出的线性交互,无自主行动
LLM 的工作完全依赖人工实时指令,是“你说一步,我做一步”的被动响应模式:
- 人工输入明确的文本指令(如“写一篇产品文案”);
- LLM 理解指令后,生成文本输出;
- 交互结束,无后续自主行动,若需继续操作,需人工再次输入新指令;
- 仅能基于当前会话的短期上下文做响应,无法记住跨会话的信息,也无法根据结果调整策略。
AI Agent:目标驱动-自主执行的闭环工作,无需人工干预
AI Agent 的工作是以目标为核心的自主闭环,是“你定目标,我做全程”的主动执行模式,核心遵循感知(Perceive)-规划(Plan)-行动(Act)-反馈(Feedback)(PPAF)的循环逻辑:
- 人工输入模糊/复杂的目标(无需明确指令,如“帮我完成本周的工作周报”);
- 感知:Agent读取外部环境信息(如本地工作文件、企业系统数据),结合自身记忆;
- 规划:将目标拆分为多个可执行的子任务,制定执行顺序和策略;
- 行动:自主调用工具完成每个子任务,获取执行结果;
- 反馈:根据工具执行的结果,判断是否符合目标要求,若不符合则调整规划和行动(如数据不全则再次调用工具获取);
- 重复3-5步,直到完成所有子任务,最终交付完整的任务成果,全程无需人工介入。
四、解决问题的维度与场景不同
LLM:解决纯语言层面、简单、即时的问题,适用于“信息输出”场景
LLM 的能力边界是语言本身,无法触达现实世界的具体操作,核心适用于:
- 内容创作(写文案、写文章、写诗);
- 知识问答(解答常识、专业知识问题);
- 语义理解(翻译、总结、提炼文本核心信息);
- 简单逻辑推理(数学题、逻辑题解答)。
这些场景的共性是:无需外部工具、无需环境交互、仅需文本输入和输出,且任务是“一次性、即时性”的。
AI Agent:解决现实世界、复杂、多步骤的问题,适用于“任务执行”场景
AI Agent 的能力边界是现实世界的具体任务,核心适用于需要规划、工具、交互、记忆的复杂场景,例如:
- 办公自动化(写周报、整理会议纪要、统计数据、发送工作邮件);
- 数据分析(获取数据、清洗数据、建模分析、生成可视化报告);
- 代码开发(需求分析、编写代码、调试运行、生成开发文档);
- 智能客服(自主理解用户问题、调用知识库/业务系统、给出解决方案、跟踪问题进度);
- 个人助手(制定旅行计划、预约机票酒店、整理日程、提醒待办事项)。
这些场景的共性是:需要拆分复杂任务、需要调用外部工具、需要与环境/系统交互、需要长期记忆,且任务是“多步骤、闭环式”的,需要从“目标”到“成果”的完整执行。
五、架构组成不同
LLM:架构单一,核心是大语言模型本身
LLM 的核心架构是Transformer+海量文本训练形成的语言模型,仅包含:
- 输入层:接收文本输入,做分词、向量化处理;
- 模型层:通过Transformer的编码器/解码器完成语义理解和生成;
- 输出层:将模型输出转化为自然文本。
原生 LLM 无其他模块,所有能力都集中在模型本身,是一个单一、封闭的系统。
AI Agent:架构复杂,是多模块协同的集成系统
AI Agent 是以大语言模型(如 GPT、Claude、文心一言)为核心大脑,整合多个功能模块形成的开放、集成系统,经典架构包含五大核心模块(缺一不可):
- 核心大脑(LLM):如 GPT,负责语义理解、逻辑推理、任务规划、决策判断,是Agent的“思维中心”;
- 感知模块:负责获取外部环境信息(如文本、文件、网络数据、软件界面、传感器数据),是Agent的“眼睛和耳朵”;
- 规划模块:负责将复杂目标拆分为子任务,制定执行策略,调整行动方案,是Agent的“大脑皮层”;
- 工具调用模块:负责对接并调用外部工具/API(如计算器、浏览器、Excel、Python、第三方业务系统),是Agent的“手脚”;
- 记忆模块:分为短期记忆(会话上下文)和长期记忆(历史任务、知识、用户偏好),负责存储、检索、复用信息,是Agent的“记忆库”。
六、二者的核心关联:LLM 是 AI Agent 的“基础底座”
AI Agent 无法脱离大语言模型独立存在,而 LLM(如 GPT)是目前最成熟、应用最广泛的 AI Agent 核心大脑,二者是组件与系统的关系:
- LLM 为 AI Agent 提供核心的认知能力(语义理解、逻辑推理、决策判断),是 Agent 能“思考”的基础;
- AI Agent 是 LLM 能力的延伸和落地,将 LLM 的“语言能力”转化为“行动能力”,让大语言模型从“纸上谈兵”变成“实际做事”;
- 除 GPT 外,Claude、Gemini、文心一言、通义千问等大语言模型也可作为 AI Agent 的核心大脑,OpenClaw 这类工具则是为 AI Agent 解决长会话上下文管理的配套技术方案(如解决 AI Agent 长任务执行中上下文溢出的问题)。
一句话总结核心区别
- LLM:能想、能说,但不会做,是解决语言问题的“智能大脑”;
- AI Agent:能想、能说、更会做,是基于 LLM(如 GPT)等大脑,装上感知、手脚、记忆,能独立完成复杂任务的“智能机器人”。
简单来说,LLM 是 AI Agent 的“灵魂”,而 AI Agent 是让这个“灵魂”拥有了身体和行动能力的完整个体。
Superpowers:面向编码 Agent 的技能框架与工作流
Superpowers 是一个基于**可组合技能(skills)**的 Agent 软件开发方法论与工作流框架,适用于 Claude Code、Cursor、Codex、OpenCode 等编码 Agent,强调「先澄清再实现」、测试驱动与子 Agent 协同。
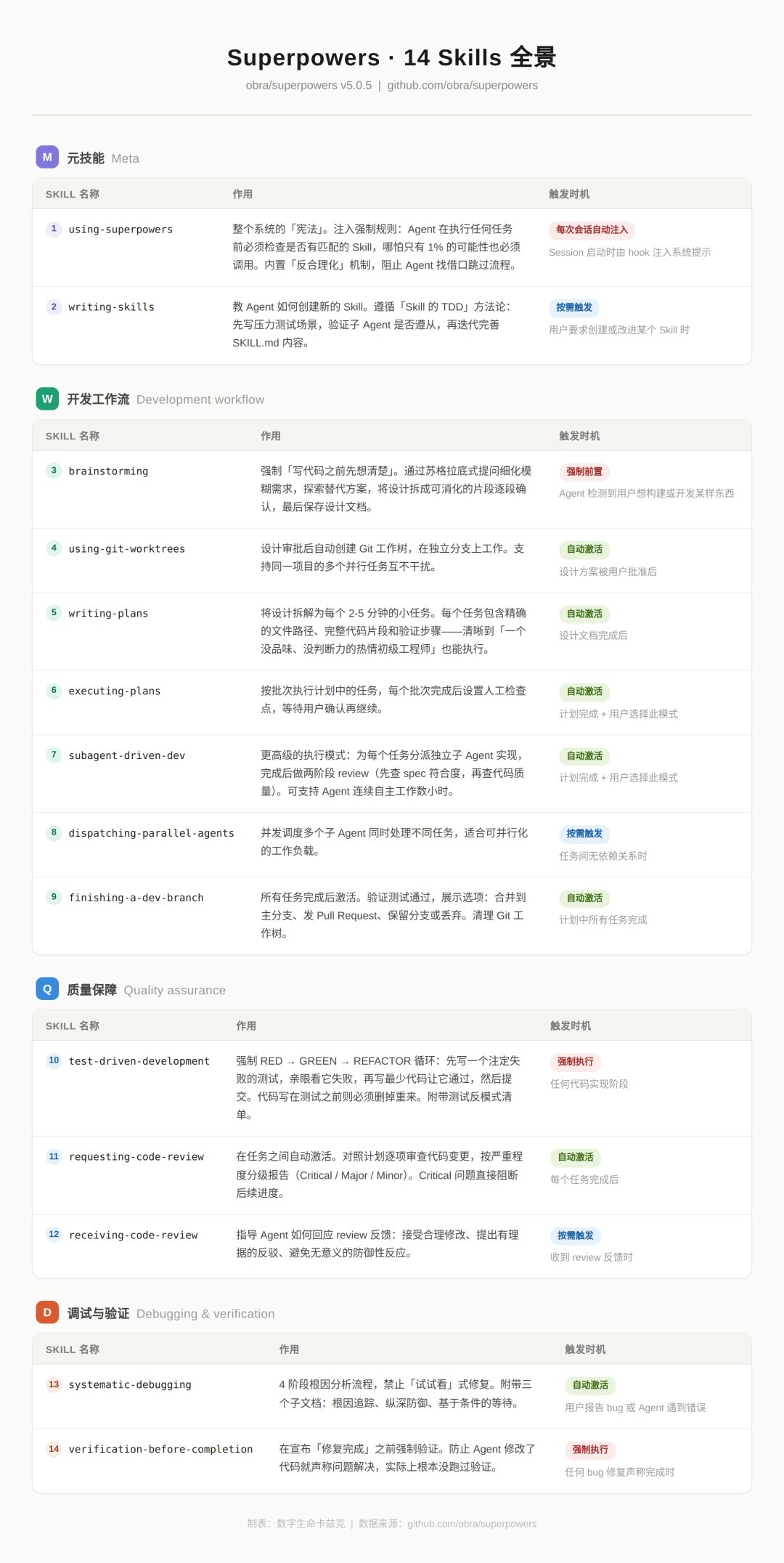
核心思路
- 不急于写代码:启动后先通过对话澄清目标,从对话中提炼出可评审的规格(spec),按小块呈现设计供确认。
- 规格驱动实现:在获得设计认可后,生成足够具体、可执行的实现计划(含文件路径、代码意图、验证步骤),再由子 Agent 按计划执行并做两阶段审查(先看是否符合规格,再看代码质量)。
- 技能自动触发:技能在适当时机自动激活,无需额外指令,即可让 Agent 按既定流程工作。
典型工作流(节选)
| 阶段 | 技能 | 作用 |
|---|---|---|
| 设计前 | brainstorming | 通过提问收敛想法、探索方案,分块呈现设计并保存设计文档 |
| 设计后 | using-git-worktrees | 在新分支上创建隔离工作区,跑项目搭建与干净测试基线 |
| 计划 | writing-plans | 将工作拆成 2~5 分钟可完成的小任务,每项含路径、代码意图与验证步骤 |
| 执行 | subagent-driven-development / executing-plans | 按任务派发子 Agent,两阶段审查或分批执行并设人工检查点 |
| 实现中 | test-driven-development | 严格 RED-GREEN-REFACTOR,先写失败测试再写最少实现,删除无测试的代码 |
| 任务间 | requesting-code-review | 对照计划做审查,按严重程度报告问题,严重问题阻塞后续 |
| 收尾 | finishing-a-development-branch | 验证测试、提供合并/PR/保留/丢弃等选项并清理 worktree |
技能库概览
- 测试:test-driven-development(含反模式参考)
- 调试:systematic-debugging(四阶段根因分析)、verification-before-completion
- 协作:brainstorming、writing-plans、executing-plans、dispatching-parallel-agents、requesting-code-review、receiving-code-review、using-git-worktrees、finishing-a-development-branch、subagent-driven-development
- 元能力:writing-skills(编写新技能)、using-superpowers(技能体系介绍)
理念简述
- 测试驱动:始终先写测试。
- 流程优先:系统化流程优于临时发挥。
- 控制复杂度:以简单为首要目标。
- 用证据说话:在宣称完成前先验证。
使用 vs 不使用 Superpowers 的效果对比
1. 开发流程规范性
| 维度 | 使用 Superpowers | 不使用 Superpowers |
|---|---|---|
| 需求梳理 | 自动触发头脑风暴,通过提问细化需求、验证设计 | 代理直接跳转到写代码,需求模糊、设计缺失 |
| 任务管理 | 拆分为 2-5 分钟小任务,路径/代码/步骤明确 | 无明确任务拆分,开发节奏混乱 |
| 版本控制 | 自动创建隔离工作区、管理分支 | 可能直接在主分支开发,缺乏隔离 |
2. 代码质量保障
| 维度 | 使用 Superpowers | 不使用 Superpowers |
|---|---|---|
| 测试驱动 | 强制 TDD,先写测试再写代码,删除无效代码 | 测试滞后或缺失,代码质量无保障 |
| 代码评审 | 自动触发多轮评审,关键问题阻断流程 | 无评审环节,问题难以及时发现 |
| 调试逻辑 | 4 阶段根因分析,修复本质问题 | 表面症状修复,易反复 |
3. 开发效率与自主性
| 维度 | 使用 Superpowers | 不使用 Superpowers |
|---|---|---|
| 代理自主性 | 可自主工作数小时,无偏差执行计划 | 需频繁人工干预,易偏离目标 |
| 协作与复用 | 技能可复用,子代理并行工作 | 无标准化协作流程,重复劳动多 |
| 流程自动化 | 全流程自动触发,无需手动指令 | 需用户逐步骤引导,效率低 |
4. 工程化成熟度
| 维度 | 使用 Superpowers | 不使用 Superpowers |
|---|---|---|
| 最佳实践遵循 | 强制 TDD、YAGNI、DRY 等原则 | 无规范约束,代码易冗余、过度设计 |
| 可维护性 | 设计文档、测试、计划完整,便于后续维护 | 文档缺失,代码可维护性差 |
| 风险控制 | 关键问题阻断、测试基线验证,降低风险 | 无风险控制,问题易累积到后期 |
Superpowers 通过标准化流程和自动化技能,让编码代理从“即兴写代码”升级为“专业工程化开发”,在质量、效率、自主性上均有质的提升。
BMad Method:敏捷 AI 驱动开发的完整框架
BMad Method(Breakthrough Method for Agile AI Driven Development,也常被解读为 Build More Architect Dreams)是一套面向 AI 驱动敏捷开发的模块化框架与生态系统,具备规模自适应的规划深度,可从修 bug 一直扩展到企业级系统。100% 开源,无付费墙。
核心特点
- AI 智能引导:随时可通过
/bmad-help获取「下一步该做什么」的指引,也可提问如「架构刚做完,接下来做什么?」。 - 规模-领域自适应:根据项目复杂度自动调整规划深度,小到单点修复、大到企业级交付均可适用。
- 结构化工作流:基于敏捷实践,覆盖分析、规划、架构与实现,提供 34+ 官方工作流。
- 多角色专家 Agent:内置 12+ 领域专家角色(如产品经理、架构师、开发者、UX、Scrum Master 等),可按需调用。
- Party Mode:支持在同一会话中引入多个 Agent 角色协作讨论,形成「多角色会议」式决策。
- 全生命周期:从头脑风暴到部署,覆盖完整开发生命周期。
安装与使用
- 环境要求:Node.js v20+
- 安装:
npx bmad-method install(或指定版本:npx bmad-method@6.0.1 install) - 非交互安装(如 CI/CD):
npx bmad-method install --directory /path/to/project --modules bmm --tools claude-code --yes - 适用 IDE:Claude Code、Cursor 等 AI 编程环境;安装后在该项目目录下打开即可使用。
模块生态
| 模块 | 用途 |
|---|---|
| BMad Method (BMM) | 核心框架,34+ 工作流 |
| BMad Builder (BMB) | 自定义 BMad Agent 与工作流 |
| Test Architect (TEA) | 基于风险的测试策略与自动化 |
| Game Dev Studio (BMGD) | 游戏开发工作流(Unity、Unreal、Godot) |
| Creative Intelligence Suite (CIS) | 创新、头脑风暴与设计思维 |
更多文档与路线图见 docs.bmad-method.org。
Superpowers 与 BMad Method 的对比
两者都致力于让 AI 辅助开发更规范、可追溯,但定位与形态不同:
| 维度 | Superpowers | BMad Method |
|---|---|---|
| 定位 | 可组合技能库 + 编码工作流,偏「方法论 + 技能」 | 完整框架 + 模块生态,偏「敏捷流程 + 多角色协作」 |
| 核心单元 | 技能(skill),如 TDD、头脑风暴、写计划、子 Agent 执行 | 工作流(workflow)+ 领域 Agent 角色(PM、架构师、开发者等) |
| 规划方式 | 先澄清再实现,规格驱动,小任务(2~5 分钟)拆解 | 规模自适应规划,从修 bug 到企业级,内置 /bmad-help 引导 |
| 协作形态 | 子 Agent 执行计划、代码评审、并行派发 | Party Mode 多角色同会话讨论 + 专家角色按需调用 |
| 生命周期 | 聚焦设计→计划→实现→评审→收尾(编码闭环) | 覆盖头脑风暴→分析→规划→架构→实现→部署(全生命周期) |
| 扩展方式 | 编写新 skill、组合现有 skill | 安装/选用官方模块(测试、游戏、创意等)+ BMad Builder 自定义 |
| 适用场景 | 单项目内「先规格、再实现」的工程化编码,强 TDD/评审 | 需要产品-架构-开发多角色协作、或跨阶段(从想法到上线)的敏捷项目 |
简要总结:Superpowers 更像「编码 Agent 的标准化技能包 + 流程」,强调规格驱动与测试驱动;BMad Method 更像「敏捷 AI 开发的操作系统」,强调多角色、全生命周期与规模自适应。二者可互补:例如用 BMad 做需求与架构阶段,用 Superpowers 的技能(如 TDD、writing-plans)规范具体实现与评审。
Skills vs MCP(扩展 Q&A)
1. 用一句话概括区别
- Skill:封装“怎么想、怎么做”——用 Markdown + 脚本,把业务规则、流程和用法打包成一个“可复用 SOP”,在本地代码执行环境里运行。 arxiv
- MCP(Model Context Protocol):封装“能连到哪里、能做什么外部动作”——用统一协议,把 Agent 和外部系统(API、数据库、SaaS、文件存储)连起来。 modelcontextprotocol
可以直接记成:Skill = 大脑里的“套路”,MCP = 对外的“总线”,CLI = 真正动手干活的工具。
2. Skill 是什么
2.1 定义与架构
在 Claude 的官方定义里,Agent Skill 是一个目录:里面有 SKILL.md、可执行脚本和参考资料,Agent 可以像在虚拟机里一样用 bash 读取和执行这些内容。 platform.claude
典型结构:
my-skill/
├─ SKILL.md # 说明 + 流程 + 约束
├─ FORMS.md # 模板/表单
├─ scripts/
│ ├─ generate.sh
│ └─ validate.py
└─ resources/
├─ db-schema.sql
└─ api-docs.md官方把 Skill 的内容分成三层,强调渐进披露: platform.claude
- 元数据(name/description):始终加载,成本 ~100 tokens/Skill
- 说明文本(SKILL.md 正文):被触发时才加载,建议控制在 < 5k tokens
- 资源和脚本:按需用 bash 读取或执行,文件本身不进上下文,只有输出消耗 tokens
这意味着 Skill 可以打包很多内容,但只有真正用到的部分才会进入上下文窗口。 platform.claude
2.2 Skill 解决什么问题
- 把“最佳实践 + 流程”写死:减少随意 prompt、提高稳定性
- 统一团队做事方式:比如统一 spec → design → ADR → tasks 的写法
- 利用现有脚本:通过 bash 调脚本完成可重复的工作,脚本本身不占 token。 arxiv
适用关键词:流程、SOP、规范、模板、项目私有逻辑。
3. MCP 是什么
3.1 定义与架构
MCP 是一个开放协议,用来在“AI 应用(Host)”和“外部系统(Server)”之间建立安全的双向连接。 databricks
架构角色通常是:
- Host:Agent 宿主,例如 Claude Code、Claude Desktop、你的自建 Agent 应用。
- Client:Host 里与某个 MCP server 对接的客户端实例。
- Server:你部署的服务,实现 MCP 规范,暴露一组 tools / resources / prompts。 huggingface
协议分两层: modelcontextprotocol
- 数据层:基于 JSON-RPC 2.0,定义 tools、resources、prompts、通知等概念。
- 传输层:支持 STDIO、本地 socket、Streamable HTTP(S) + SSE 等,对上屏蔽底层细节。 snyk
3.2 MCP 解决什么问题
- 统一对接外部系统:数据库、内部 HTTP API、SaaS、云服务、文件存储等。 cloud.google
- 让多个 Host / IDE 共享同一组工具:VS Code、Claude Desktop 等都可以连同一个 MCP server。 databricks
- 在企业场景里做权限、鉴权和审计:用 OAuth、API Key 等标准方式控制访问。 developer.ibm
适用关键词:多系统集成、企业级接入、跨项目共享能力、统一鉴权。
4. 关键区别对照表
| 维度 | Skills | MCP |
|---|---|---|
| 核心目标 | 教 Agent 怎么做(流程、规则、模板) | 让 Agent 能做什么外部动作(对接系统) |
| 技术形态 | 目录 + SKILL.md + 本地脚本/资源 | JSON-RPC + Host/Client/Server 架构 |
| 运行位置 | Host 提供的代码执行环境(沙箱/容器) platform.claude | 独立进程或远程服务,通过 STDIO / HTTP / SSE 通信 modelcontextprotocol |
| 上下文成本 | 渐进披露:元数据常驻,正文按需加载,脚本本身不进上下文 platform.claude | 工具 schema + 参数 + 返回值都走 JSON-RPC,工具多时 schema 会推高 token 成本 reddit |
| 适合内容 | 项目工作流、编写规范、审查流程、模板、团队规则 | DB/API/SaaS/监控/仓库搜索等基础设施能力 |
| 部署维护 | Git 管理 + 拷目录即可;适合项目/团队级 | 需要部署和维护 server;适合组织/平台级 modelcontextprotocol |
| 复用粒度 | 偏“项目内复用”或“团队内共享模板” | 偏“多项目、多 Host 共用同一基础能力” |
| 与 CLI 的关系 | 典型模式是在 Skill 中通过 bash 调 CLI/脚本 | MCP server 也可以内部调用 CLI,但对 Host 来说是远程工具 |
5. 推荐组合方式:Skill 写剧本,CLI/MCP 执行动作
社区比较认同的组合是:Skill = 行为剧本,CLI/MCP = 道具和后台服务。 reddit
5.1 Skill + CLI(项目内)
适合:单个仓库、团队私有 workflow、spec / design / ADR / PR / 部署脚本等。
- Skill 里定义:
- 什么时候跑测试、什么时候生成设计文档、什么时候写 ADR。
- 输出格式、检查清单、失败时如何回退。
- Skill 调用本地 CLI:
npm test、make build、./deploy.sh、./generate-docs。
优点:
- 全程走现有脚本,调试简单;
- 文件和脚本都在 Git 下,review 成本低;
- Skill 脚本本身不占 token,输出才占。 platform.claude
5.2 Skill + MCP(组织层)
适合:需要接几十个内部系统、统一鉴权/审计、跨 IDE 共用工具的场景。
- MCP server 暴露统一工具:如
get_incidents、query_orders、run_k8s_job。 - Skill 负责把调用顺序和业务规则写清:
- 例如“生成上线变更设计 → 调用
get_incidents检查近期风险 → 调用run_canary→ 生成报告”。
- 例如“生成上线变更设计 → 调用
6. Q&A 拓展:为什么有人说 “MCP 已死,Skill + CLI 才是正解?”
Q:社区为什么会出现 “MCP 已死” 这种说法?
A:主要不是说协议真的没用,而是很多人发现“在大部分开发者日常场景里,用 Skill + CLI 比 MCP 更轻、更省钱、更好调试”,于是出现了这种极端表达。 cnblogs
典型理由包括:
- Token / 上下文成本
下面是一个最小但规范的 MCP 工具 schema 例子
这是一个叫 get_weather 的工具:输入城市名,返回当前天气信息。
{
"name": "get_weather",
"title": "Weather Information Provider",
"description": "Get current weather information for a given location.",
"inputSchema": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "City name or zip code, e.g. 'Singapore' or '10001'."
},
"units": {
"type": "string",
"description": "Temperature units: 'metric' (C) or 'imperial' (F).",
"enum": ["metric", "imperial"],
"default": "metric"
}
},
"required": ["location"],
"additionalProperties": false
},
"outputSchema": {
"type": "object",
"properties": {
"location": { "type": "string" },
"temperature": { "type": "number" },
"units": { "type": "string" },
"description": { "type": "string" }
},
"required": ["location", "temperature", "units"],
"additionalProperties": true
},
"annotations": {
"category": "weather",
"rateLimit": "60 requests/minute"
},
"execution": {
"taskSupport": "optional"
}
}实现和运维门槛
- 写 MCP server 要处理 JSON-RPC、连接、鉴权和错误恢复,感觉像在搭一套小型微服务。
- 写 CLI 则可以完全用现有 DevOps 知识(bash、Python、Go 等),部署、日志、监控都复用现有体系。 baoyu
适用范围不对称
- MCP 的优势在“多 Host、多项目共享工具 + 企业级治理”,而很多人只是单仓库用一个 Agent 写代码,对他们来说 MCP 带来的结构化收益远小于引入的复杂度。 shengwang
所以在一些文章和帖子里,你会看到类似结论:
“对 80% 的日常项目开发,Skill + CLI 足够,甚至更好;MCP 更多是企业集成总线,不再是每个人每天要碰的东西。” juejin
Q:那 MCP 真的“死”了吗?
A:没有。更准确的描述是:它从“大家都应该用的新玩具”,变成了“适合特定场景的基础设施”。 cloud.tencent
反向观点主要是:
- 对需要统一鉴权、多租户、审计和安全边界的大公司来说,让所有 AI 应用通过 MCP 接系统,比每个团队自己写 CLI + HTTP 要可控得多。 anthropic
- 在多 Agent / 多 Host 场景下,用 MCP 做“统一能力层”,比每个客户端单独接几十个 API 要好治理。 developer.ibm
所以,“MCP 已死”更像一句情绪化缩写:
“在大部分本地开发 / 单项目场景里,不要一上来就上 MCP,Skill + CLI 通常更合适。”
Q:如何在自己的项目里做取舍?
一个实用决策树:
- 这件事主要是规范流程、写文档、跑脚本?
→ 优先用 Skill + CLI。 - 这件事需要对接公司统一 API / 数据源 / SaaS,还要兼容多个 IDE / Agent?
→ 考虑做成 MCP server,在组织层统一接入。 - 同一个能力要被很多项目、很多团队长期复用?
→ MCP 作为“平台能力层”更合适;Skill 更适合作为“项目侧的使用手册和编排层”。